Retrieval-Augmented Generation Is Just the Beginning- The Rise of Agentic and Graph-Based RAG
Retrieval-Augmented Generation (RAG) was sold as the silver bullet.
Just add a retriever.
Pull in a few documents.
Prepend them to the prompt.
Boom hallucinations gone. Accuracy saved. Production ready.
Except… reality didn’t quite agree.
RAG worked great in demos but in production?
-
Sometimes the model retrieved the wrong stuff.
-
Sometimes the right stuff but from the wrong place.
-
Sometimes the answer needed reasoning across multiple facts not just a paragraph dump.
-
And sometimes… the best answer wasn’t in any single document.
So no , RAG didn’t fail.
Our mental model of RAG was simply too small.
Let’s zoom out.
Why LLMs Need RAG in the First Place
Classic LLMs answer questions using only what’s stored inside their parameters:
That works — until you care about things like:
-
fresh information
-
niche domains
-
correctness
-
auditability
So RAG extends the model with external knowledge retrieved at inference time:
Now knowledge is:
✔ updatable
✔ controllable
✔ inspectable
This single shift made RAG inevitable.
But the first generation of RAG was far too naive.
Classic RAG: Great Idea, Oversimplified Execution
The original RAG pipeline looked like this:
-
Embed the query
-
Retrieve top-k similar documents
-
Stuff them into the context
-
Ask the LLM to answer
Formally:
Where similarity ≈ cosine similarity in embedding space.
This works well for:
✔ single-hop questions
✔ small text collections
✔ FAQ-like use cases
But it silently assumes similarity = usefulness.
That’s wrong.
Retrieval Is Not About Similarity - It’s About Reducing Uncertainty
The real objective of retrieval isn’t to find stuff that looks similar.
It’s to retrieve information that makes the answer more certain.
Information theory gives us the right lens:
Where
Meaning:
You don’t just want “related” documents -
you want documents that actually matter to the answer.
This is the point where RAG had to evolve.
Modular RAG: Stop Treating Retrieval as a Single Box
The first upgrade wasn’t AI - it was architecture.
Instead of one monolithic pipeline, Modular RAG breaks retrieval into clean components:
-
retriever
-
reranker
-
summarizer / compressor
-
generator
Now context assembly becomes:
This gives you:
✔ pluggable components
✔ measurable performance
✔ domain-aware tuning
This is the difference between:
“Play with embeddings and hope”
and
“Engineer a retrieval system”
But modularity still doesn’t solve the big problem:
retrieval itself requires reasoning.
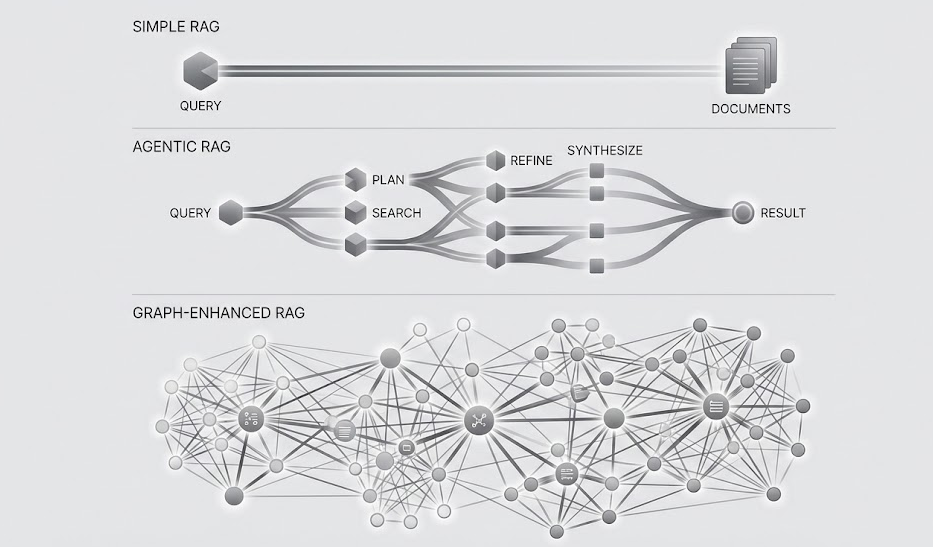
Agentic RAG: Retrieval as a Decision-Making Process
Here’s the key shift:
Retrieval is not a step in the pipeline.
Retrieval is a policy over time.
In Agentic RAG, the system can:
-
plan
-
retrieve
-
reflect
-
retrieve again
-
verify
-
then answer
So instead of one-shot retrieval, we now have:
Where:
This mirrors how humans research:
“I don’t know yet — let me look up this part first.
Now I get it — now I need one more source…”
Agentic RAG shines when:
✔ The question needs multiple steps
✔ The answer must be verified
✔ The context must evolve as the model learns
This is RAG growing up.
But Text Isn’t Enough - Enter Graph-Enhanced RAG
Text is linear.
Knowledge is not.
Real-world knowledge is relational:
-
entities
-
relationships
-
hierarchies
-
causality
-
time-dependencies
Graph-Enhanced RAG models knowledge as:
Where:
-
(V) = nodes (entities)
-
(E) = edges (relationships)
Retrieval then becomes:
Now the model retrieves a structured subgraph, not a blob of paragraphs.
This unlocks:
✔ multi-hop reasoning
✔ entity-level grounding
✔ relationship-aware answers
Perfect for:
-
enterprise knowledge graphs
-
scientific data
-
legal/compliance
-
medical reasoning
Anywhere relationships matter.
So… When Do You Use What?
Here’s the simple mental model 👇
|Your Problem Looks Like…|Use This| |---|---| |Simple fact lookup|Classic / Modular RAG| |Multi-step reasoning|Agentic RAG| |Entity + relationship heavy|Graph-Enhanced RAG| |Enterprise search|Modular + Graph RAG| |Full autonomous workflows|Agentic + Graph RAG|
RAG isn’t one technique anymore.
It’s an ecosystem of architectures.
The Future: RAG as External Memory - Not Lookup
Here’s the real punchline.
RAG is evolving from:
“fetch a few documents”
into:
“an adaptive external memory + reasoning engine”
Where context updates function almost like Bayesian belief updates:
Meaning:
the system continuously refines what it “knows” during inference.
That’s no longer retrieval.
That’s cognition.
Final Thought
RAG didn’t stop at “retrieve and prepend” because we wanted something fancier.
It evolved because real-world reasoning requires it.
Once LLMs left the lab:
-
retrieval had to become modular
-
retrieval had to become agentic
-
retrieval had to become structured
RAG is no longer about finding documents.
It’s about deciding what the model should know next.
And that changes everything.